Using eisaR for Exon-Intron Split Analysis (EISA)
Michael Stadler
2025-11-03
Source:vignettes/eisaR.Rmd
eisaR.RmdIntroduction
Exon-Intron Split Analysis has been described by Gaidatzis et al. (2015). It consists of separately quantifying exonic and intronic alignments in RNA-seq data, in order to measure changes in mature RNA and pre-mRNA reads across different experimental conditions. We have shown that this allows quantification of transcriptional and post-transcriptional regulation of gene expression.
The eisaR package contains convenience functions to
facilitate the steps in an exon-intron split analysis, which consists
of: 1. preparing the annotation (exonic and gene body coordinate ranges,
section @ref(annotation)) 2. quantifying RNA-seq alignments in exons and
introns (sections @ref(align) and @ref(count)) 3. calculating and
comparing exonic and intronic changes across conditions (section
@ref(convenient)) 4. visualizing the results (section @ref(plot))
For the steps 1. and 2. above, this vignette makes use of Bioconductor annotation and the QuasR package. It is also possible to obtain count tables for exons and introns using some other pipeline or approach, and directly start with step 3.
Installation
To install the eisaR package, start R and enter:
# BiocManager is needed to install Bioconductor packages
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
# Install eisaR
BiocManager::install("eisaR")Preparing the annotation
As mentioned, eisaR uses gene annotations from
Bioconductor. They are provided in the form of TxDb or
EnsDb objects, e.g. via packages such as TxDb.Mmusculus.UCSC.mm10.knownGene
or EnsDb.Hsapiens.v86.
You can see available annotations using the following code:
If you would like to use an alternative source of gene annotations,
you might still be able to use eisaR by first converting
your annotations into a TxDb or an EnsDb (for
creating a TxDb see makeTxDb in the txdbmaker
package, for creating an EnsDb see
makeEnsembldbPackage in the ensembldb
package).
For this example, eisaR contains a small
TxDb to illustrate how regions are extracted. We will load
it from a file. Alternatively, the object would be loaded using
library(...), for example using
library(TxDb.Mmusculus.UCSC.mm10.knownGene).
# load package
library(eisaR)
# get TxDb object
txdbFile <- system.file("extdata", "hg19sub.sqlite", package = "eisaR")
txdb <- AnnotationDbi::loadDb(txdbFile)Exon and gene body regions are then extracted from the
TxDb:
# extract filtered exonic and gene body regions
regS <- getRegionsFromTxDb(txdb = txdb, strandedData = TRUE)
#> extracting exon coordinates
#> total number of genes/exons: 12/32
#> removing overlapping/single-exon/ambiguous genes (8)
#> creating filtered regions for 4 genes (33.3%) with 20 exons (62.5%)
regU <- getRegionsFromTxDb(txdb = txdb, strandedData = FALSE)
#> extracting exon coordinates
#> total number of genes/exons: 12/32
#> removing overlapping/single-exon/ambiguous genes (9)
#> creating filtered regions for 3 genes (25%) with 17 exons (53.1%)
lengths(regS)
#> exons genebodies
#> 20 4
lengths(regU)
#> exons genebodies
#> 17 3
regS$exons
#> GRanges object with 20 ranges and 0 metadata columns:
#> seqnames ranges strand
#> <Rle> <IRanges> <Rle>
#> ENSG00000078808 chr1 17278-18194 -
#> ENSG00000078808 chr1 18828-21741 -
#> ENSG00000078808 chr1 23614-23747 -
#> ENSG00000078808 chr1 24202-24358 -
#> ENSG00000078808 chr1 27799-27854 -
#> ... ... ... ...
#> ENSG00000186891 chr1 5740-6070 -
#> ENSG00000186891 chr1 6755-7081 -
#> ENSG00000254999 chr3 2266-2513 +
#> ENSG00000254999 chr3 12300-12402 +
#> ENSG00000254999 chr3 12943-13884 +
#> -------
#> seqinfo: 3 sequences from an unspecified genomeAs you can see, the filtering procedure removes slightly more genes
for unstranded data (strandedData = FALSE), as overlapping
genes cannot be discriminated even if they reside on opposite
strands.
You can also export the obtained regions into files. This may be
useful if you plan to align and/or quantify reads outside of R. For
example, you can use rtracklayer
to export the regions in regS into .gtf
files:
Quantify RNA-seq alignments in exons and introns
For this example we will use the QuasR package for indexing and alignment of short reads, and a small RNA-seq dataset that is contained in that package. As mentioned, it is also possible to align or also quantify your reads using an alternative aligner/counter, and skip over these steps. For more details about the syntax, we refer to the documentation and vignette of the QuasR package.
Align reads
Let’s first copy the sample data from the QuasR
package to the current working directory, all contained in a folder
named extdata:
library(QuasR)
#> Loading required package: parallel
#> Loading required package: Rbowtie
file.copy(system.file(package = "QuasR", "extdata"), ".", recursive = TRUE)
#> [1] TRUEWe next align the reads to a mini-genome (fasta file
extdata/hg19sub.fa) using qAlign. The
sampleFile specifies the samples we want to use, and the
paths to the respective fastq files.
sampleFile <- file.path("extdata", "samples_rna_single.txt")
## Display the structure of the sampleFile
read.delim(sampleFile)
#> FileName SampleName
#> 1 rna_1_1.fq.bz2 Sample1
#> 2 rna_1_2.fq.bz2 Sample1
#> 3 rna_2_1.fq.bz2 Sample2
#> 4 rna_2_2.fq.bz2 Sample2
## Perform the alignment
proj <- qAlign(sampleFile = sampleFile,
genome = file.path("extdata", "hg19sub.fa"),
aligner = "Rhisat2", splicedAlignment = TRUE)
#> Creating .fai file for: /Users/runner/work/eisaR/eisaR/vignettes/extdata/hg19sub.fa
#> alignment files missing - need to:
#> create alignment index for the genome
#> create 4 genomic alignment(s)
#> Creating an Rhisat2 index for /Users/runner/work/eisaR/eisaR/vignettes/extdata/hg19sub.fa
#> Finished creating index
#> Testing the compute nodes...OK
#> Loading QuasR on the compute nodes...preparing to run on 1 nodes...done
#> Available cores:
#> sat12-dp150-e33d4706-362a-453b-a769-bd6c2169939c-A6584E4C099E.local: 1
#> Performing genomic alignments for 4 samples. See progress in the log file:
#> /Users/runner/work/eisaR/eisaR/vignettes/QuasR_log_36435eee1e49.txt
#> Genomic alignments have been created successfully
alignmentStats(proj)
#> seqlength mapped unmapped
#> Sample1:genome 95000 5961 43
#> Sample2:genome 95000 5914 86Count alignments in exons and gene bodies
Alignments in exons and gene bodies can now be counted using
qCount and the regU that we have generated
earlier (assuming that the data is unstranded). Intronic counts can then
be obtained from the difference between gene bodies and exons:
cntEx <- qCount(proj, regU$exons, orientation = "any")
#> counting alignments...done
#> collapsing counts by sample...done
#> collapsing counts by query name...done
cntGb <- qCount(proj, regU$genebodies, orientation = "any")
#> counting alignments...done
#> collapsing counts by sample...done
cntIn <- cntGb - cntEx
cntEx
#> width Sample1 Sample2
#> ENSG00000078808 4837 705 1065
#> ENSG00000186827 1821 37 8
#> ENSG00000186891 1470 26 2
cntIn
#> width Sample1 Sample2
#> ENSG00000078808 10307 5 15
#> ENSG00000186827 1012 3 0
#> ENSG00000186891 1734 3 0As mentioned, both alignments and counts can also be obtained using alternative approaches. It is required that the two resulting exon and intron count tables have identical structure (genes in rows, samples in columns, the same order of rows and columns in both tables).
Load full count tables
The above example only contains very few genes. For the rest of the
vignette, we will use count tables from a real RNA-seq experiment that
are provided in the eisaR package. The counts correspond to
the raw data used in Figure 3a of Gaidatzis et
al. (2015) and are also available online from the supplementary
material:
cntEx <- readRDS(system.file("extdata",
"Fig3abc_GSE33252_rawcounts_exonic.rds",
package = "eisaR"))
cntIn <- readRDS(system.file("extdata",
"Fig3abc_GSE33252_rawcounts_intronic.rds",
package = "eisaR"))Run EISA conveniently
All the further steps in exon-intron split analysis can now be
performed using a single function runEISA. If you prefer to
perform the analysis step-by-step, you can skip now to section
@ref(stepwise).
# remove "width" column
rEx <- cntEx[, colnames(cntEx) != "width"]
rIn <- cntIn[, colnames(cntIn) != "width"]
# create condition factor (contrast will be TN - ES)
cond <- factor(c("ES", "ES", "TN", "TN"))
# run EISA
res <- runEISA(rEx, rIn, cond)
#> filtering quantifyable genes...keeping 11759 from 20288 (58%)
#> fitting statistical model...done
#> calculating log-fold changes...doneAlternative implementations of EISA
There are six arguments in runEISA
(modelSamples, geneSelection,
effects, statFramework, pscnt and
sizeFactor) that control gene filtering, calculation of
contrasts and the statistical method used, summarized in the bullet list
below.
The default values of these arguments correspond to the currently
recommended way of running EISA. You can also run EISA exactly as it was
described by Gaidatzis et al. (2015), by
setting method = "Gaidatzis2015". This will override the
values of the six other arguments and set them according to the
published algorithm (as indicated below).
-
modelSamples: Account for individual samples in statistical model? Possible values are:-
FALSE(method="Gaidatzis2015"): use a model of the form~ condition * region -
TRUE(default): use a model adjusting for the baseline differences among samples, and with condition-specific region effects (similar to the model described in section 3.5 of the edgeR user guide)
-
-
geneSelection: How to select detected genes. Possible values are:-
"filterByExpr"(default): First, counts are normalized usingedgeR::calcNormFactors, treating intronic and exonic counts as individual samples. Then, theedgeR::filterByExprfunction is used with default parameters to select quantifiable genes. -
"none": This will use all the genes provided in the count tables, assuming that an appropriate selection of quantifiable genes has already been done. -
"Gaidatzis2015"(method="Gaidatzis2015"): First, intronic and exonic counts are linearly scaled to the mean library size (estimated as the sum of all intronic or exonic counts, respectively). Then, quantifiable genes are selected as the genes with countsxthat fulfilllog2(x + 8) > 5in both exons and introns.
-
-
statFramework: The framework withinedgeRthat is used for the statistical analysis. Possible values are:-
"QLF"(default): quasi-likelihood F-test usingedgeR::glmQLFitandedgeR::glmQLFTest. This framework is highly recommended as it gives stricter error rate control by accounting for the uncertainty in dispersion estimation. -
"LRT"(method="Gaidatzis2015"): likelihood ratio test usingedgeR::glmFitandedgeR::glmLRT.
-
-
effects: How the effects (log2 fold-changes) are calculated. Possible values are:-
"predFC"(default): Fold-changes are calculated using the fitted model withedgeR::predFCand the value provided topscnt. Please note that if a sample factor is included in the statistical model (modelSamples=TRUE), effects cannot be obtained from that model. In that case, effects are obtained from a simpler model without sample effects. -
"Gaidatzis2015"(method="Gaidatzis2015"): Fold-changes are calculated using the formulalog2((x + pscnt)/(y + pscnt)). Ifpscntis not set to 8,runEISAwill warn that this deviates from the method used in Gaidatzis et al., 2015.
-
pscnt: The pseudocount that is added to normalized counts before log transformation. ForgeneSelection="Gaidatzis2015",pscntis used both in gene selection as well as in the calculation of log2 fold-changes. Otherwise,pscntis only used in the calculation of log2 fold-changes inedgeR::predFC(, prior.count = pscnt).-
sizeFactor: How size factors (TMM normalization factors and library sizes) are calculated and used withineisaR:-
"exon"(default): Size factors are calculated for exonic counts and reused for the corresponding intronic counts. -
"intron": Size factors are calculated for intronic counts and reused for the corresponding exonic counts. -
"individual"(method="Gaidatzis2015"): Size factors are calculated independently for exonic and intronic counts.
-
While different values for these arguments typically yield similar
results, the defaults are often less stringent compared to
method="Gaidatzis2015" when selecting quantifiable genes,
but more stringent when calling significant changes (especially with low
numbers of replicates).
Here is an illustration of how the results differ between
method="Gaidatzis2015" and the defaults:
res1 <- runEISA(rEx, rIn, cond, method = "Gaidatzis2015")
#> setting parameters according to Gaidatzis et al., 2015
#> filtering quantifyable genes...keeping 8481 from 20288 (41.8%)
#> fitting statistical model...done
#> calculating log-fold changes...done
res2 <- runEISA(rEx, rIn, cond)
#> filtering quantifyable genes...keeping 11759 from 20288 (58%)
#> fitting statistical model...done
#> calculating log-fold changes...done
# number of quantifiable genes
nrow(res1$DGEList)
#> [1] 8481
nrow(res2$DGEList)
#> [1] 11759
# number of genes with significant post-transcriptional regulation
sum(res1$tab.ExIn$FDR < 0.05)
#> [1] 476
sum(res2$tab.ExIn$FDR < 0.05)
#> [1] 139
# method="Gaidatzis2015" results contain most of default results
summary(rownames(res2$contrasts)[res2$tab.ExIn$FDR < 0.05] %in%
rownames(res1$contrasts)[res1$tab.ExIn$FDR < 0.05])
#> Mode FALSE TRUE
#> logical 46 93
# comparison of deltas
ids <- intersect(rownames(res1$DGEList), rownames(res2$DGEList))
cor(res1$contrasts[ids, "Dex"], res2$contrasts[ids, "Dex"])
#> [1] 0.9897323
cor(res1$contrasts[ids, "Din"], res2$contrasts[ids, "Din"])
#> [1] 0.9893353
cor(res1$contrasts[ids, "Dex.Din"], res2$contrasts[ids, "Dex.Din"])
#> [1] 0.9673239
plot(res1$contrasts[ids, "Dex.Din"], res2$contrasts[ids, "Dex.Din"], pch = "*",
xlab = expression(paste(Delta, "exon", -Delta, "intron for method='Gaidatzis2015'")),
ylab = expression(paste(Delta, "exon", -Delta, "intron for default parameters")))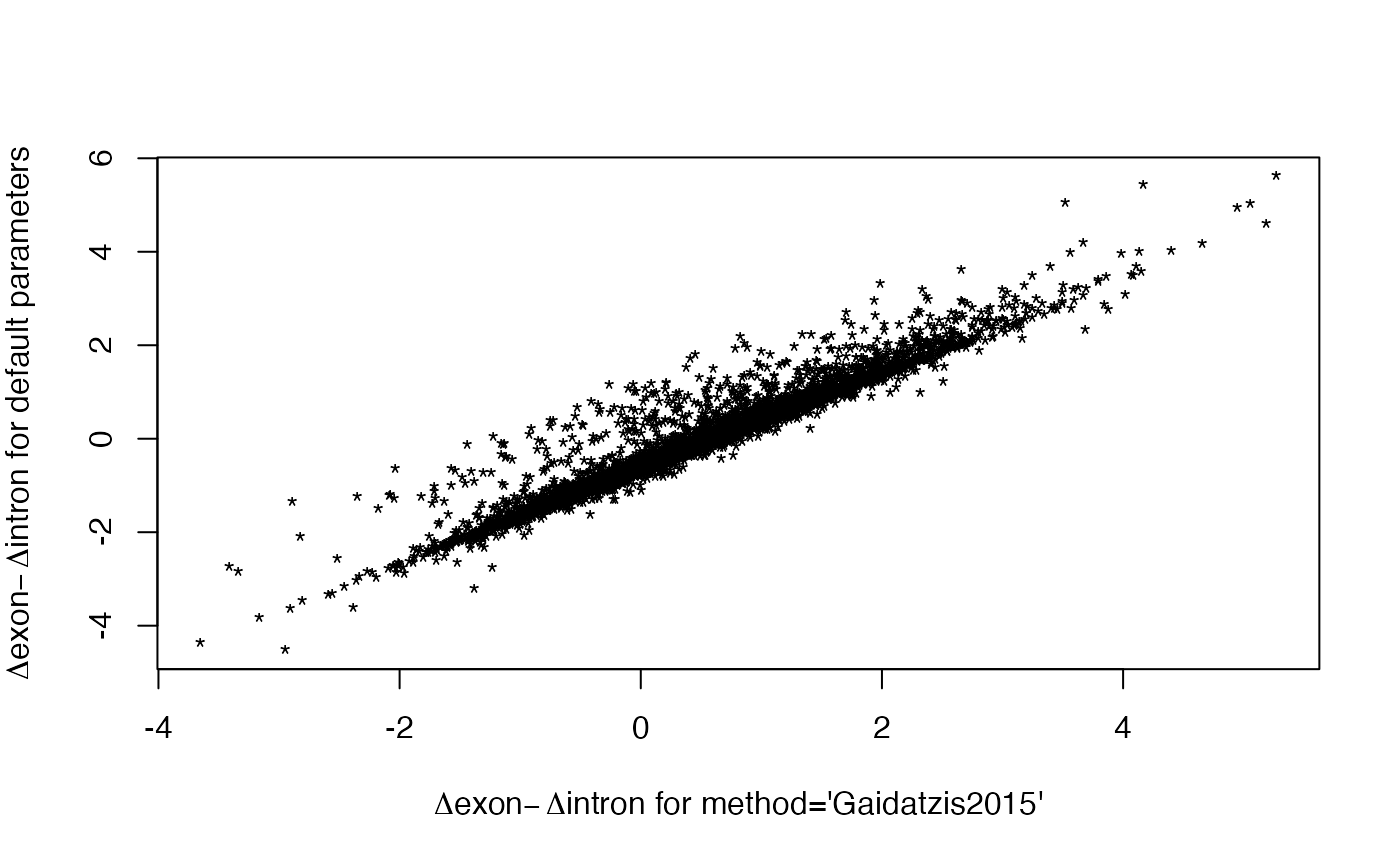
On the estimation of interactions in a split-plot design experiment
The calculation of the significance of interactions (here whether the fold-changes differ between exonic or intronic data) is well defined for experimental designs where all samples are independent from one another. Within EISA, this is not the case (each sample yields two data points, one for exons and one for introns). That results in a dependency between data points: If a sample is affected by a problem in the experiment, it might at the same time give rise to outlier values in both exonic and intronic counts.
In statistics, such an experimental design is often referred to as a
split-plot design, and a recommended way to analyze interactions in such
experiments would be to use a mixed effect model with the plot (in our
case, the sample) as a random effect. The disadvantage here however
would be that available packages for mixed effect models are not
designed for count data, and we therefore use an alternative approach to
explicitly model the sample dependency, by introducing sample-specific
columns into the design matrix (for modelSamples=TRUE).
That sample factor is nested in the condition factor (no sample can
belong to more than one condition). Thus, we are in the situation
described in section 3.5 (‘Comparisons both between and within
subjects’) of the edgeR user
guide, and we use the approach described there to define a design matrix
with sample-specific baseline effects as well as condition-specific
region effects.
This has no impact on the effects (the log2 fold-changes of
modelSamples=TRUE and modelSamples=FALSE are
nearly identical). However, in the presence of sample effects,
modelSamples=TRUE increases the sensitivity of detecting
genes with significant interactions. Here is a comparison of the EISA
results with and without accounting for the sample in the model:
res3 <- runEISA(rEx, rIn, cond, modelSamples = FALSE)
#> filtering quantifyable genes...keeping 11034 from 20288 (54.4%)
#> fitting statistical model...done
#> calculating log-fold changes...done
res4 <- runEISA(rEx, rIn, cond, modelSamples = TRUE)
#> filtering quantifyable genes...keeping 11759 from 20288 (58%)
#> fitting statistical model...done
#> calculating log-fold changes...done
ids <- intersect(rownames(res3$contrasts), rownames(res4$contrasts))
# number of genes with significant post-transcriptional regulation
sum(res3$tab.ExIn$FDR < 0.05)
#> [1] 5
sum(res4$tab.ExIn$FDR < 0.05)
#> [1] 139
# modelSamples=TRUE results are a super-set of
# modelSamples=FALSE results
summary(rownames(res3$contrasts)[res3$tab.ExIn$FDR < 0.05] %in%
rownames(res4$contrasts)[res4$tab.ExIn$FDR < 0.05])
#> Mode TRUE
#> logical 5
# comparison of contrasts
diag(cor(res3$contrasts[ids, ], res4$contrasts[ids, ]))
#> Dex Din Dex.Din
#> 0.9931269 0.9872622 0.9912675
plot(res3$contrasts[ids, 3L], res4$contrasts[ids, 3L], pch = "*",
xlab = "Interaction effects for modelSamples=FALSE",
ylab = "Interaction effects for modelSamples=TRUE")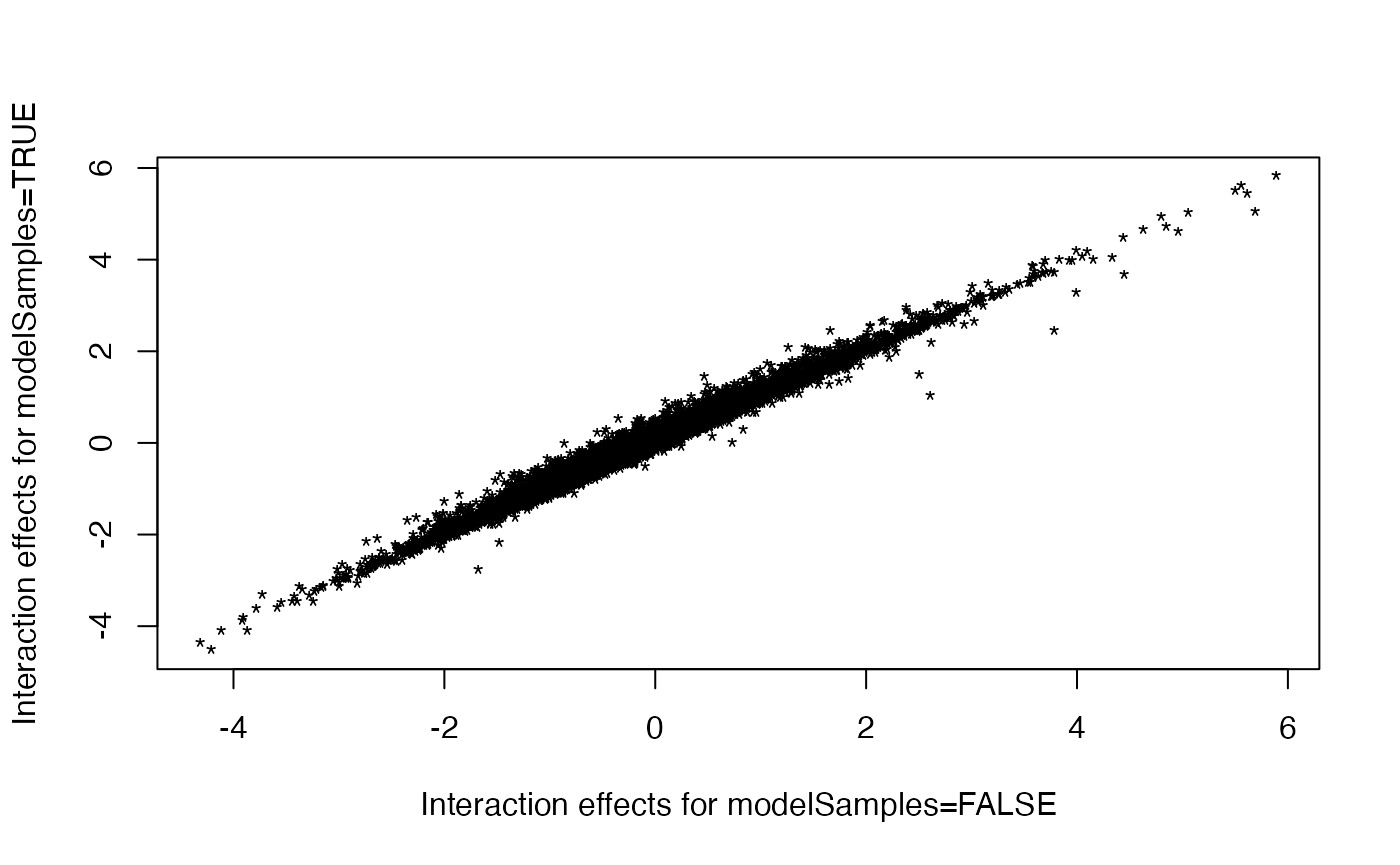
# comparison of interaction significance
plot(-log10(res3$tab.ExIn[ids, "FDR"]), -log10(res4$tab.ExIn[ids, "FDR"]), pch = "*",
xlab = "-log10(FDR) for modelSamples=FALSE",
ylab = "-log10(FDR) for modelSamples=TRUE")
abline(a = 0.0, b = 1.0, col = "gray")
legend("bottomright", "y = x", bty = "n", lty = 1L, col = "gray")
Visualize EISA results
We can now visualize the results by plotting intronic changes versus exonic changes (genes with significant interactions, which are likely to be post-transcriptionally regulated, are color coded):
plotEISA(res)
#> identified 139 genes to highlight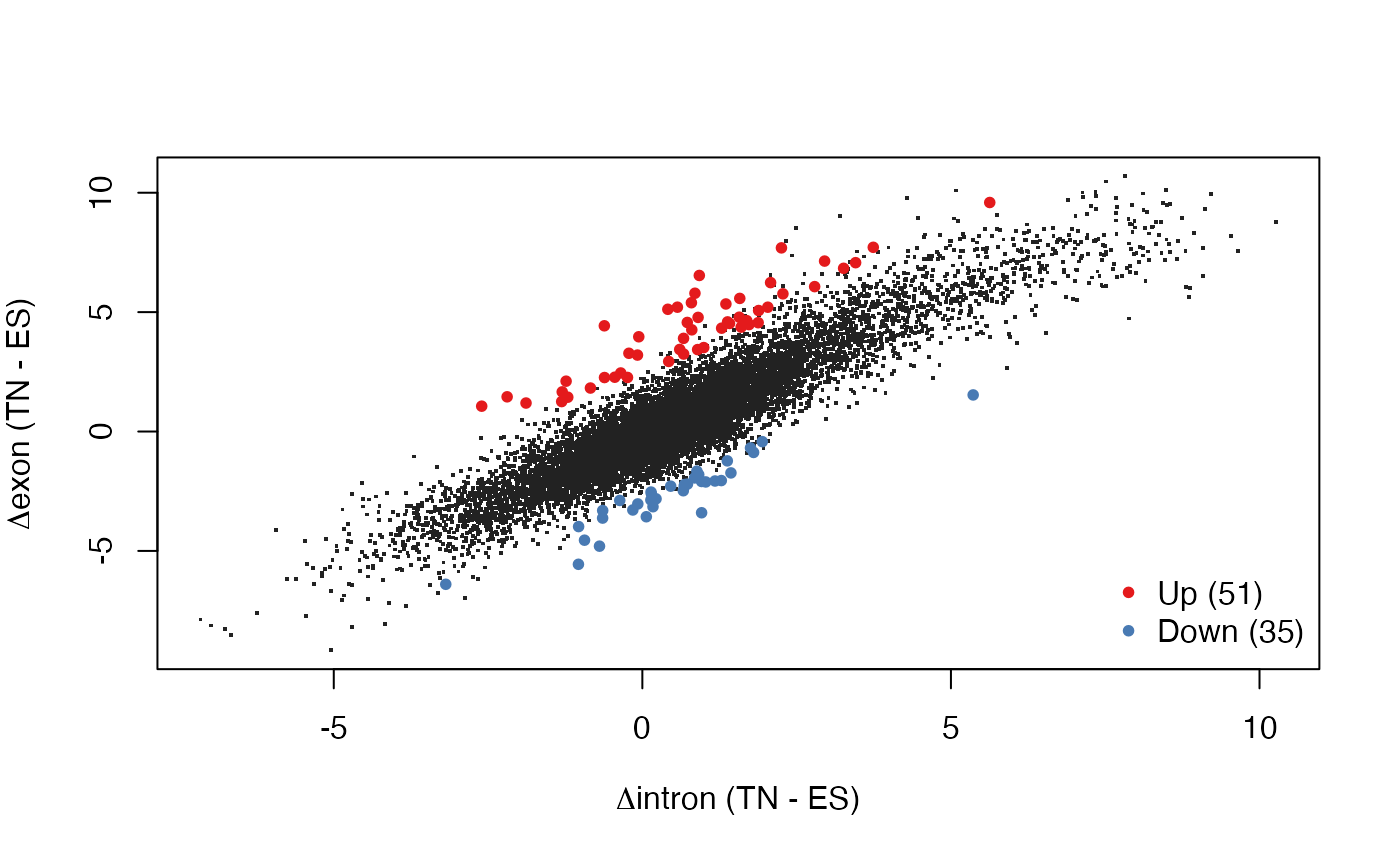
Run EISA step-by-step
As an alternative to runEISA (section @ref(convenient))
and plotEISA (section @ref(plot)) described above, you can
also analyze the data step-by-step as described in Gaidatzis et al. (2015). This may be preferable
to understand each individual step and be able to access intermediate
results.
The results obtained in this way are identical to what you get with
runEISA(..., method = "Gaidatzis2015"), so if you are happy
with runEISA you can skip the rest of the vignette.
Normalization
Normalization is performed separately on exonic and intronic counts, assuming that varying exon over intron ratios between samples are of technical origin.
# remove column "width"
rEx <- cntEx[, colnames(cntEx) != "width"]
rIn <- cntIn[, colnames(cntIn) != "width"]
rAll <- rEx + rIn
fracIn <- colSums(rIn) / colSums(rAll)
summary(fracIn)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 0.2696 0.2977 0.3105 0.3459 0.3587 0.4929
# scale counts to the mean library size,
# separately for exons and introns
normEx <- t(t(rEx) / colSums(rEx) * mean(colSums(rEx)))
normIn <- t(t(rIn) / colSums(rIn) * mean(colSums(rIn)))
# log transform (add a pseudocount of 8)
lognormEx <- log2(normEx + 8L)
lognormIn <- log2(normIn + 8L)Identify quantifiable genes
Genes with very low counts in either exons or introns are better removed, as they will be too noisy to yield useful results. We use here a fixed cut-off on the normalized, log-transformed intron and exonic counts:
Calculate , and
The count tables were obtained from a total RNA-seq experiments in mouse embryonic stem (MmES) cells and derived terminal neurons (MmTN), with two replicates for each condition.
We will now calculate the changes between neurons and ES cells in introns (), in exons (), and the difference between the two ():
Dex <- lognormEx[, c("MmTN_RNA_total_a", "MmTN_RNA_total_b")] -
lognormEx[, c("MmES_RNA_total_a", "MmES_RNA_total_b")]
Din <- lognormIn[, c("MmTN_RNA_total_a", "MmTN_RNA_total_b")] -
lognormIn[, c("MmES_RNA_total_a", "MmES_RNA_total_b")]
Dex.Din <- Dex - Din
cor(Dex[quantGenes, 1L], Dex[quantGenes, 2L])
#> [1] 0.9379397
cor(Din[quantGenes, 1L], Din[quantGenes, 2L])
#> [1] 0.8449252
cor(Dex.Din[quantGenes, 1L], Dex.Din[quantGenes, 2L])
#> [1] 0.5518187Both exonic and intronic changes are correlated across replicates, and so are the differences, indicating a reproducible signal for post-transcriptional regulation.
Statistical analysis
Finally, we use the replicate measurement in the edgeR framework to calculate the significance of the changes:
# create DGEList object with exonic and intronic counts
library(edgeR)
#> Loading required package: limma
#>
#> Attaching package: 'limma'
#> The following object is masked from 'package:BiocGenerics':
#>
#> plotMA
cnt <- data.frame(Ex = rEx, In = rIn)
y <- DGEList(counts = cnt, genes = data.frame(ENTREZID = rownames(cnt)))
# select quantifiable genes and normalize
y <- y[quantGenes, ]
y <- calcNormFactors(y)
# design matrix with interaction term
region <- factor(c("ex", "ex", "ex", "ex", "in", "in", "in", "in"),
levels = c("in", "ex"))
cond <- rep(factor(c("ES", "ES", "TN", "TN")), 2L)
design <- model.matrix(~ region * cond)
rownames(design) <- colnames(cnt)
design
#> (Intercept) regionex condTN regionex:condTN
#> Ex.MmES_RNA_total_a 1 1 0 0
#> Ex.MmES_RNA_total_b 1 1 0 0
#> Ex.MmTN_RNA_total_a 1 1 1 1
#> Ex.MmTN_RNA_total_b 1 1 1 1
#> In.MmES_RNA_total_a 1 0 0 0
#> In.MmES_RNA_total_b 1 0 0 0
#> In.MmTN_RNA_total_a 1 0 1 0
#> In.MmTN_RNA_total_b 1 0 1 0
#> attr(,"assign")
#> [1] 0 1 2 3
#> attr(,"contrasts")
#> attr(,"contrasts")$region
#> [1] "contr.treatment"
#>
#> attr(,"contrasts")$cond
#> [1] "contr.treatment"
# estimate model parameters
y <- estimateDisp(y, design)
fit <- glmFit(y, design)
# calculate likelihood-ratio between full and reduced models
lrt <- glmLRT(fit)
# create results table
tt <- topTags(lrt, n = nrow(y), sort.by = "none")
head(tt$table[order(tt$table$FDR, decreasing = FALSE), ])
#> ENTREZID logFC logCPM LR PValue FDR
#> 14680 14680 6.374810 6.554051 98.57271 3.133076e-23 2.657161e-19
#> 75209 75209 5.338969 6.400361 90.66369 1.702900e-21 7.221148e-18
#> 93765 93765 3.849862 6.603142 52.66559 3.954589e-13 1.117962e-09
#> 17957 17957 4.342520 6.864176 51.82395 6.070689e-13 1.287138e-09
#> 268354 268354 9.855391 8.402066 50.92879 9.577842e-13 1.624594e-09
#> 19276 19276 5.165167 8.391296 48.24000 3.771160e-12 5.330535e-09Visualize the results
Finally, we visualize the results by plotting intronic changes versus exonic changes (genes with significant interactions, which are likely to be post-transcriptionally regulated, are color coded):
sig <- tt$table$FDR < 0.05
sum(sig)
#> [1] 521
sigDir <- sign(tt$table$logFC[sig])
cols <- ifelse(sig,
ifelse(tt$table$logFC > 0.0, "#E41A1CFF", "#497AB3FF"),
"#22222244")
# volcano plot
plot(tt$table$logFC, -log10(tt$table$FDR), col = cols, pch = 20L,
xlab = expression(paste("RNA change (log2 ", Delta, "exon/", Delta, "intron)")),
ylab = "Significance (-log10 FDR)")
abline(h = -log10(0.05), lty = 2L)
abline(v = 0.0, lty = 2L)
ppar <- par("usr")
text(x = ppar[1L] + 3.0 * par("cxy")[1L],
y = ppar[4L], adj = c(0.0, 1.0),
labels = sprintf("n=%d", sum(sigDir == -1L)), col = "#497AB3FF")
text(x = ppar[2L] - 3.0 * par("cxy")[1L],
y = ppar[4L], adj = c(1.0, 1.0),
labels = sprintf("n=%d", sum(sigDir == 1L)), col = "#E41A1CFF")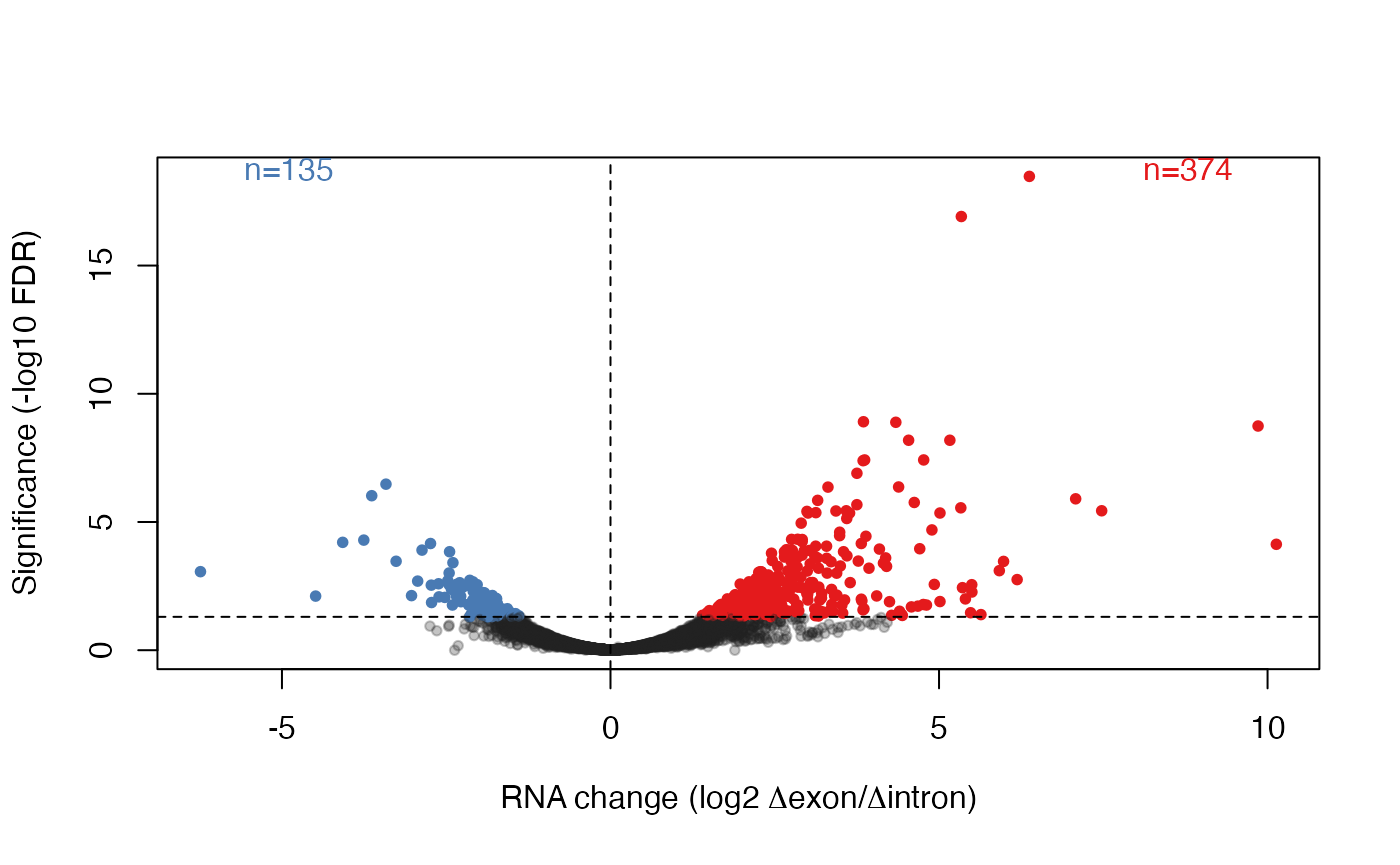
# Delta I vs. Delta E
plot(rowMeans(Din)[quantGenes], rowMeans(Dex)[quantGenes], pch = 20L, col = cols,
xlab = expression(paste(Delta, "intron (log2 TN/ES)")),
ylab = expression(paste(Delta, "exon (log2 TN/ES)")))
legend(x = "bottomright", bty = "n", pch = 20L, col = c("#E41A1CFF", "#497AB3FF"),
legend = sprintf("%s (%d)", c("Up", "Down"), c(sum(sigDir == 1L), sum(sigDir == -1L))))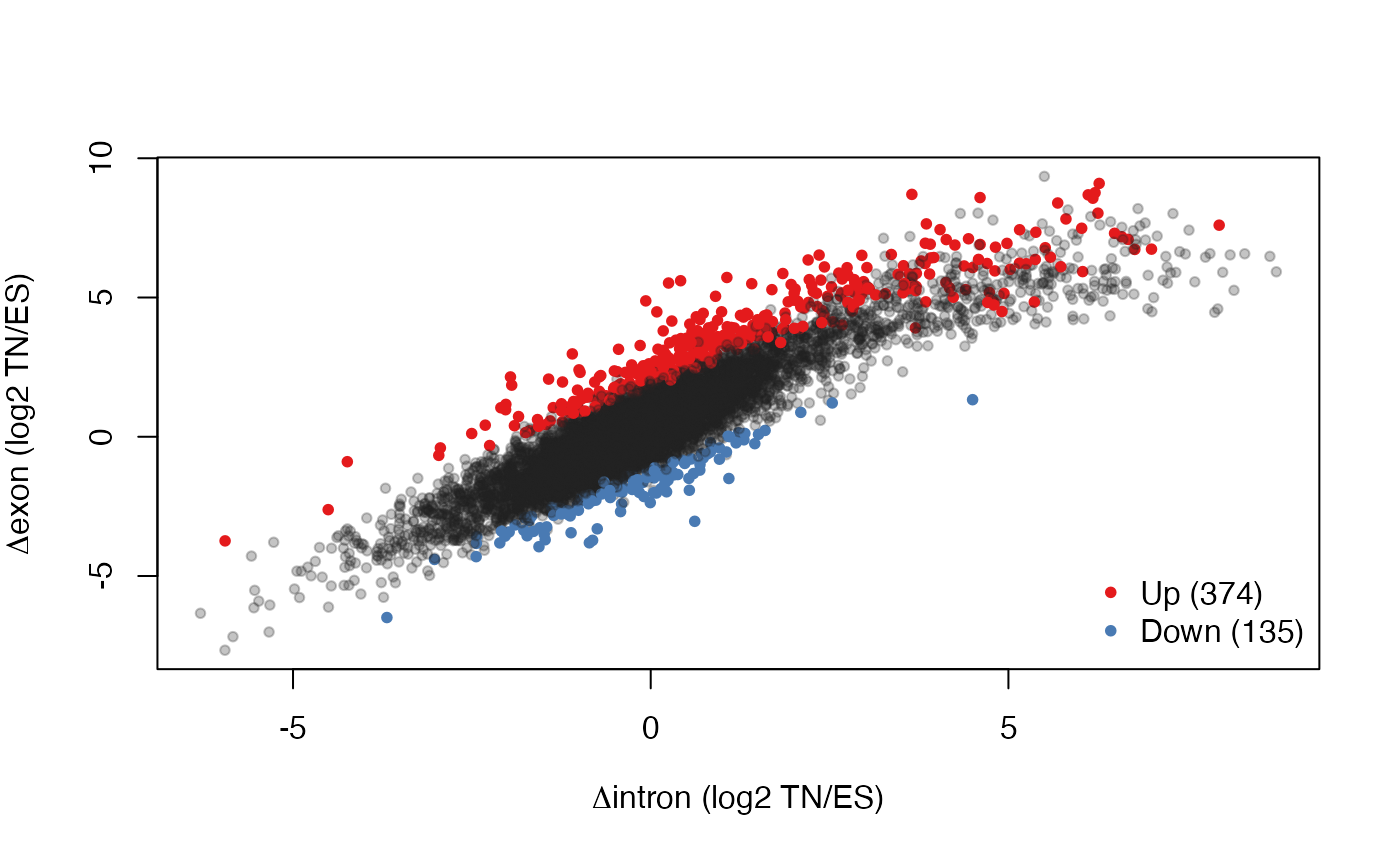
Session information
The output in this vignette was produced under:
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Sequoia 15.7.1
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> time zone: UTC
#> tzcode source: internal
#>
#> attached base packages:
#> [1] parallel stats4 stats graphics grDevices utils datasets
#> [8] methods base
#>
#> other attached packages:
#> [1] edgeR_4.8.0 limma_3.66.0 QuasR_1.50.0
#> [4] Rbowtie_1.50.0 rtracklayer_1.70.0 GenomicFeatures_1.62.0
#> [7] AnnotationDbi_1.72.0 Biobase_2.70.0 GenomicRanges_1.62.0
#> [10] Seqinfo_1.0.0 IRanges_2.44.0 S4Vectors_0.48.0
#> [13] BiocGenerics_0.56.0 generics_0.1.4 eisaR_1.23.1
#> [16] BiocStyle_2.38.0
#>
#> loaded via a namespace (and not attached):
#> [1] DBI_1.2.3 bitops_1.0-9
#> [3] deldir_2.0-4 httr2_1.2.1
#> [5] biomaRt_2.66.0 rlang_1.1.6
#> [7] magrittr_2.0.4 Rhisat2_1.26.0
#> [9] matrixStats_1.5.0 compiler_4.5.2
#> [11] RSQLite_2.4.3 png_0.1-8
#> [13] systemfonts_1.3.1 vctrs_0.6.5
#> [15] txdbmaker_1.6.0 stringr_1.5.2
#> [17] pwalign_1.6.0 pkgconfig_2.0.3
#> [19] crayon_1.5.3 fastmap_1.2.0
#> [21] dbplyr_2.5.1 XVector_0.50.0
#> [23] Rsamtools_2.26.0 rmarkdown_2.30
#> [25] UCSC.utils_1.6.0 ragg_1.5.0
#> [27] bit_4.6.0 xfun_0.54
#> [29] cachem_1.1.0 cigarillo_1.0.0
#> [31] GenomeInfoDb_1.46.0 jsonlite_2.0.0
#> [33] progress_1.2.3 blob_1.2.4
#> [35] DelayedArray_0.36.0 BiocParallel_1.44.0
#> [37] jpeg_0.1-11 prettyunits_1.2.0
#> [39] R6_2.6.1 VariantAnnotation_1.56.0
#> [41] stringi_1.8.7 bslib_0.9.0
#> [43] RColorBrewer_1.1-3 jquerylib_0.1.4
#> [45] Rcpp_1.1.0 bookdown_0.45
#> [47] SummarizedExperiment_1.40.0 knitr_1.50
#> [49] SGSeq_1.44.0 igraph_2.2.1
#> [51] Matrix_1.7-4 tidyselect_1.2.1
#> [53] abind_1.4-8 yaml_2.3.10
#> [55] codetools_0.2-20 RUnit_0.4.33.1
#> [57] hwriter_1.3.2.1 curl_7.0.0
#> [59] lattice_0.22-7 tibble_3.3.0
#> [61] ShortRead_1.68.0 KEGGREST_1.50.0
#> [63] evaluate_1.0.5 desc_1.4.3
#> [65] BiocFileCache_3.0.0 Biostrings_2.78.0
#> [67] pillar_1.11.1 BiocManager_1.30.26
#> [69] filelock_1.0.3 MatrixGenerics_1.22.0
#> [71] RCurl_1.98-1.17 hms_1.1.4
#> [73] GenomicFiles_1.46.0 glue_1.8.0
#> [75] tools_4.5.2 interp_1.1-6
#> [77] BiocIO_1.20.0 BSgenome_1.78.0
#> [79] locfit_1.5-9.12 GenomicAlignments_1.46.0
#> [81] fs_1.6.6 XML_3.99-0.19
#> [83] grid_4.5.2 latticeExtra_0.6-31
#> [85] restfulr_0.0.16 cli_3.6.5
#> [87] rappdirs_0.3.3 textshaping_1.0.4
#> [89] S4Arrays_1.10.0 dplyr_1.1.4
#> [91] sass_0.4.10 digest_0.6.37
#> [93] SparseArray_1.10.1 rjson_0.2.23
#> [95] memoise_2.0.1 htmltools_0.5.8.1
#> [97] pkgdown_2.1.3.9000 lifecycle_1.0.4
#> [99] httr_1.4.7 statmod_1.5.1
#> [101] bit64_4.6.0-1